
A novel learning algorithm, namely orthogonal weights modification, with the addition of a context-dependent processing module, was proposed by scholars from CASIA, which equipped the artificial neural networks with powerful abilities for continuous learning and contextual-dependent learning, and successfully overcame catastrophic forgetting. Related work has been published online by Nature Machine Intelligence.
Artificial Intelligence has become one of the most challenging scientific frontiers in 21st century. But what is the exact “Artificial Intelligence”? It can be sure that flexibility is a hallmark of high-level intelligence. Human and non-human primates can respond differently to the same stimulus under different contexts.
Obviously, human brains are the best illustration of high flexibility, which can not only keep learning in new environment, but also can adjust behaviors to different contexts. Comparatively, current deep neural networks (DNNs) lack sufficient flexibility to work in complex situations, which, on one hand, are always trapped by catastrophic forgetting and hard to retain the previously acquired knowledge while learning the new, i.e. lacking of continual learning ability, and on the other hand, can only finish the pre-trained tasks while unable to respond to the changes in real situations, i.e. lacking of contextual-dependent learning ability. These constitute a significant gap in the abilities between the current DNNs and primate brains.
Recently, scholars from the Briannetome Research Center and the National Laboratory of Pattern Recognition made breakthroughs on tackling the above questions, which sheds lights on the flexibility research for artificial intelligence system. Their works are recorded in Continual Learning of Context-dependent Processing in Neural Networks. Guanxiong Zeng, a graduate student from CASIA, and Yang Chen, a postdoctor from CASIA, along with other co-authors, propose an approach, including an orthogonal weight modification (OWM) algorithm and a context-dependent processing (CDP) module, which enables a neural network to progressively learn various mapping rules in a context-dependent way. In addition, by using the CDP module to enable contextual information to modulate the representation of sensory features, a network can learn different, context-specific mappings for even identical stimuli, which greatly enhances the flexibility and adaptability.
The core of OWM algorithm is: when training a network for new tasks, its weights can only be modified in the direction orthogonal to the subspace spanned by all previously learned inputs. This ensures that new learning processes do not interfere with previously learned tasks, as weight changes in the network as a whole do not interact with old inputs. Consequently, combined with a gradient descent-based search, the OWM helps the network to find a weight configuration that can accomplish new task while ensuring the performance of learned tasks remains unchanged. This is achieved by first constructing a projector used to find the direction orthogonal to the input space P. The learning-induced modification of weights is determined by △W=κP△WBP, where△WBP is the weights adjustment calculated according to the standard back propagation.
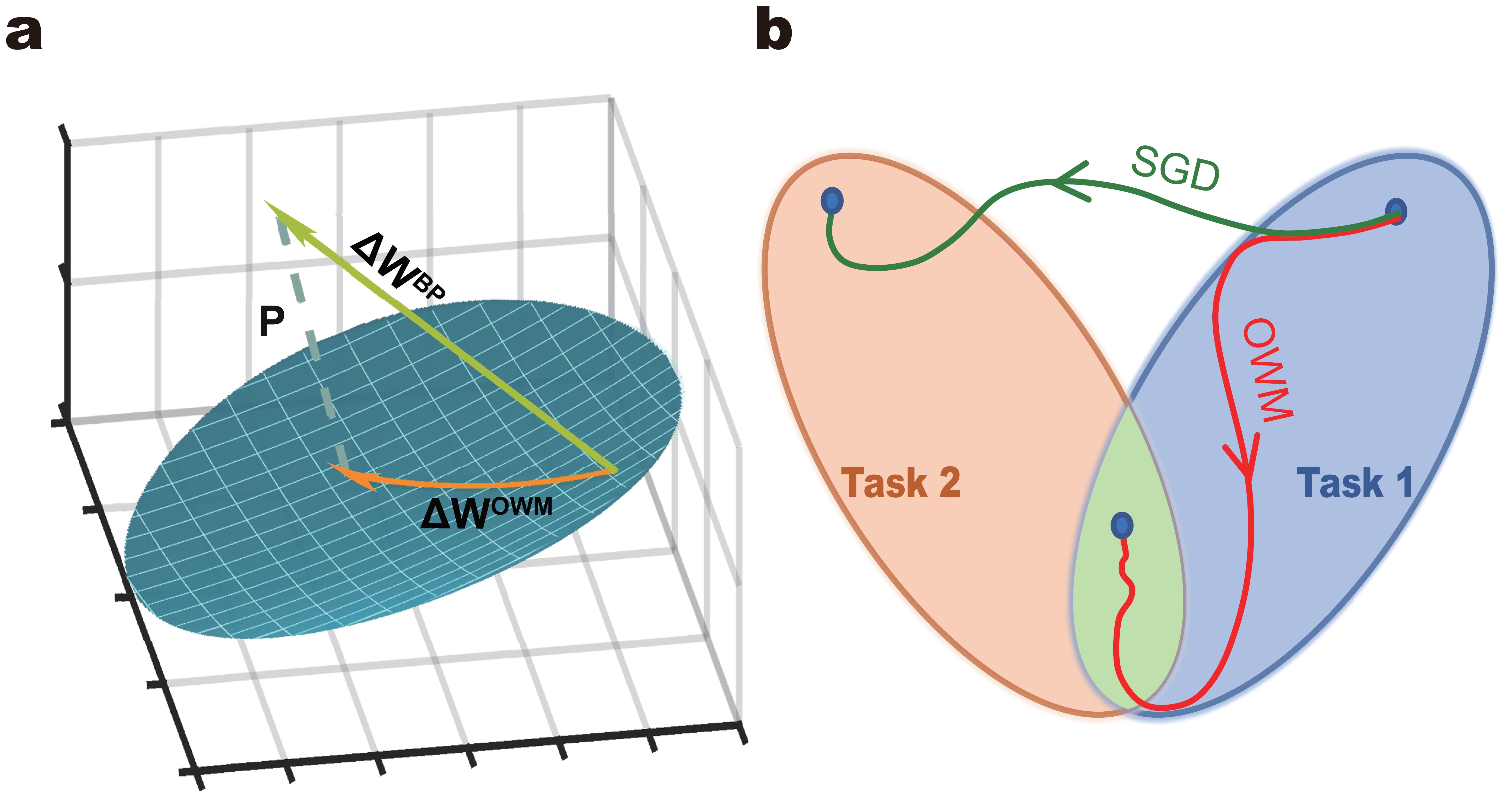
Schematic of OWM
OWM realizes effectively retaining the previously acquired knowledge while is compatible with the present gradient back propagation algorithm, which presents a good performance in continual-learning test. The experiments on disjoint MNIST and shuffled MNIST demonstrate that OWM result in either superior or equal performance compared with other continual learning methods without storage of previous task samples or dynamically adding new nodes to the network. What’s more, OWM exhibits significant performance improvement over other methods as learning tasks increase. It is also found that a classifier trained with the OWM could learn to recognize all 3,755 Chinese characters sequentially. Similar results are obtained with the ImageNet dataset, where the classifier trained by the OWM combined with a pre-trained feature extractor was able to learn 1,000 classes of natural images sequentially. Specifically, continual learning with small sample size achieved by OWM in recognizing Chinese characters is also satisfying. Taking the handwritten characters recognition as example, the feature extractor trained with few samples could support the classifier to sequentially learn more new characters, demonstrating that the network could sequentially learn new categories not previously encountered.
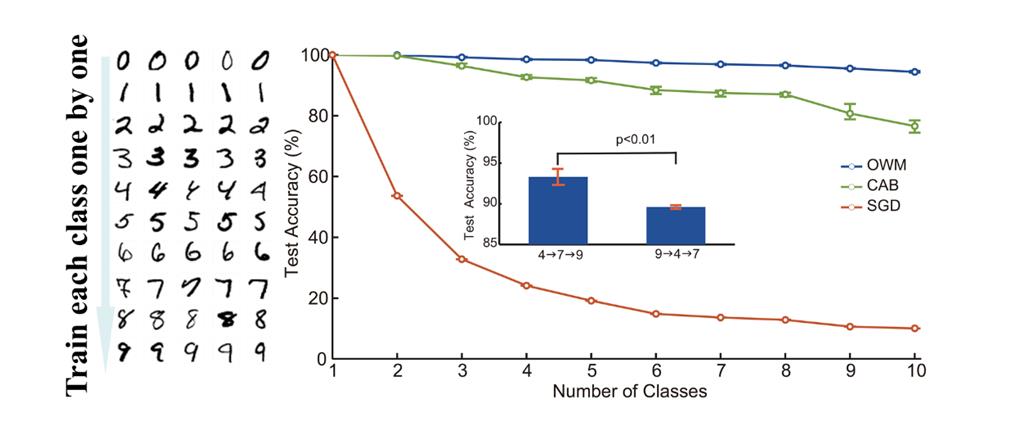
Performance of OWM, CAB and SGD in the ten-task disjoint MNIST experiment. performance of recognizing digit ‘9’ was significantly higher after learning digits ‘7’ and ‘4’; two-sided t-test was applied to assess statistical significance.

OWM performs well in continual learning task with the ImageNet database and handwritten characters recognition.
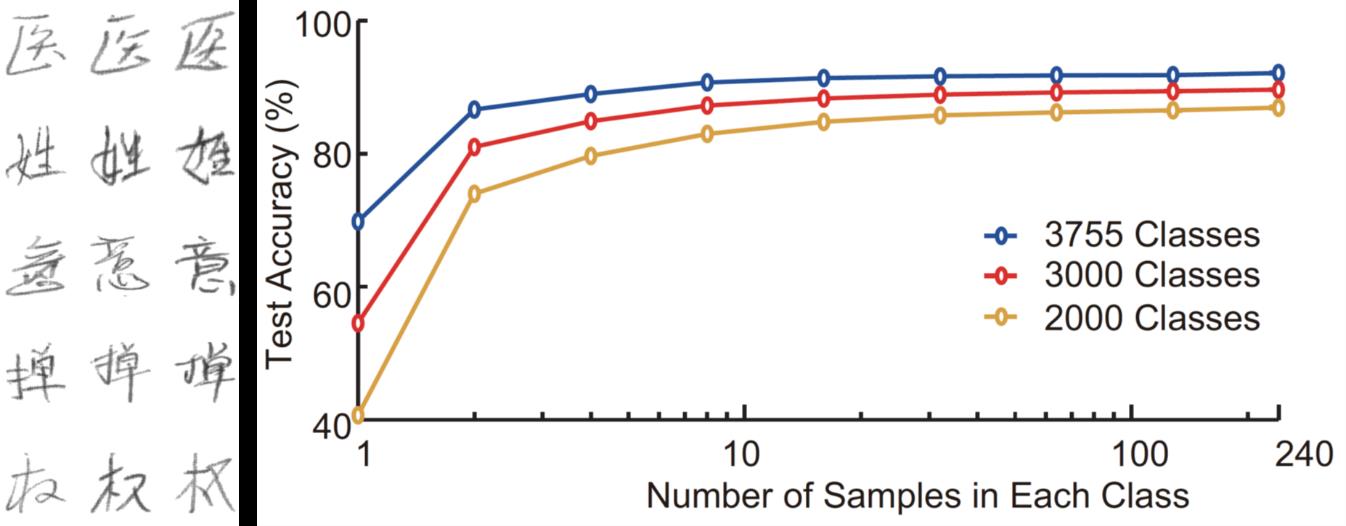
Continual learning with small sample size achieved by OWM in recognizing Chinese characters
Although a system that can learn many different mapping rules in an online and sequential manner is highly desirable, such a system cannot accomplish context-dependent learning by itself. To achieve that, contextual information needs to interact with sensory information properly. Here the paper adopts a solution inspired by the pre-frontal cortex (PFC). The PFC receives sensory inputs as well as contextual information, which enables it to choose sensory features most relevant to the present task to guide action. To mimic this architecture, the paper adds the CDP module before the OWM-trained classifier, which is fed with both sensory feature vectors and contextual information. The CDP module consists of an encoder sub-module, which transforms contextual information to proper controlling signals, and a ‘rotator’ sub-module, which uses controlling signals to manipulate the processing of sensory inputs.
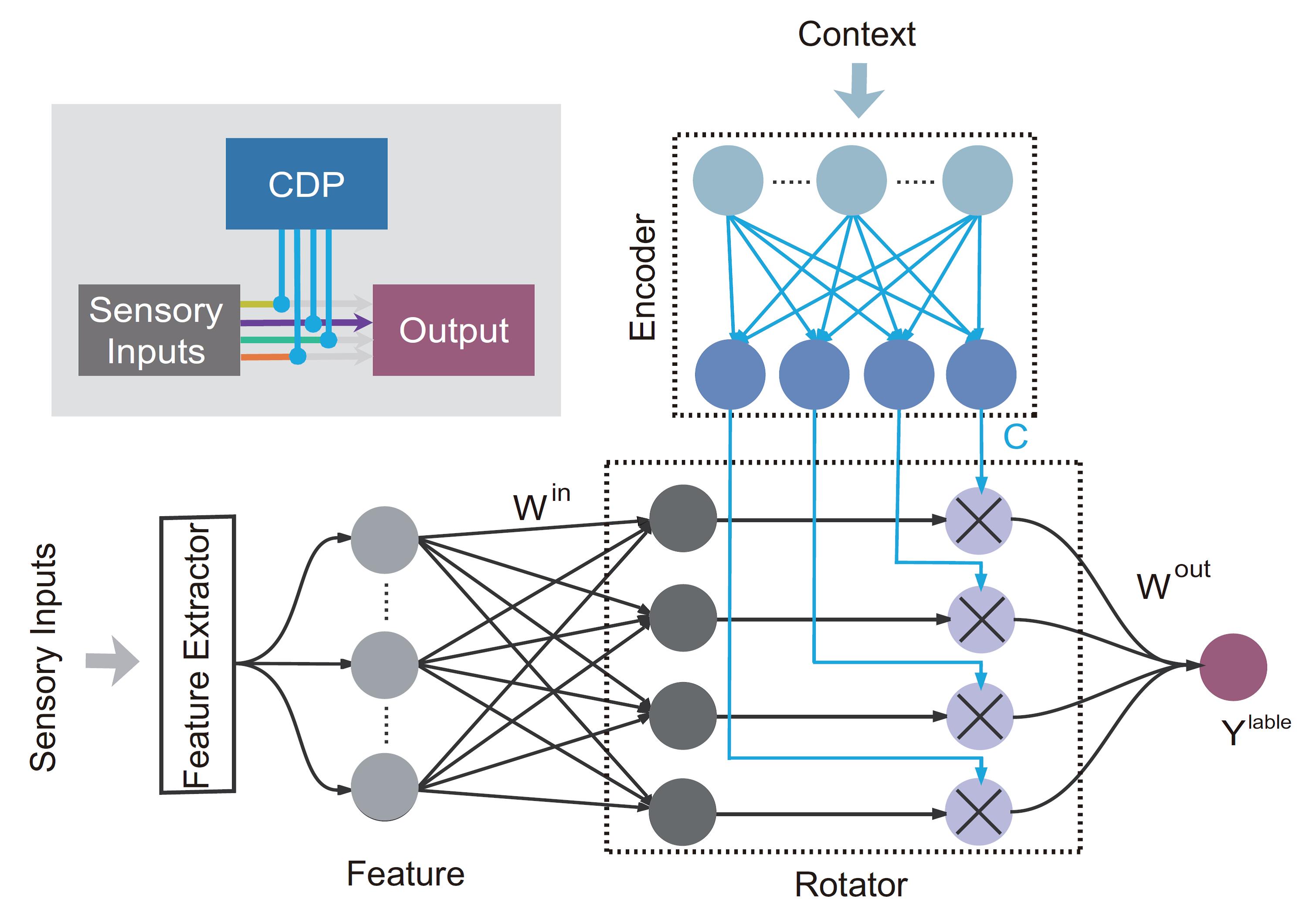
The CDP module that mimics the pre-frontal cortex. Schematic of network architecture is in the upper left side.
After combining CDP module with OWM algorithm, the system can sequentially learn 40 different, context-specific mapping rules with a single classifier. The accuracy is very close to that achieves by multi-task training, in which the network is trained to classify all 40 attributes using 40 separate classifiers.
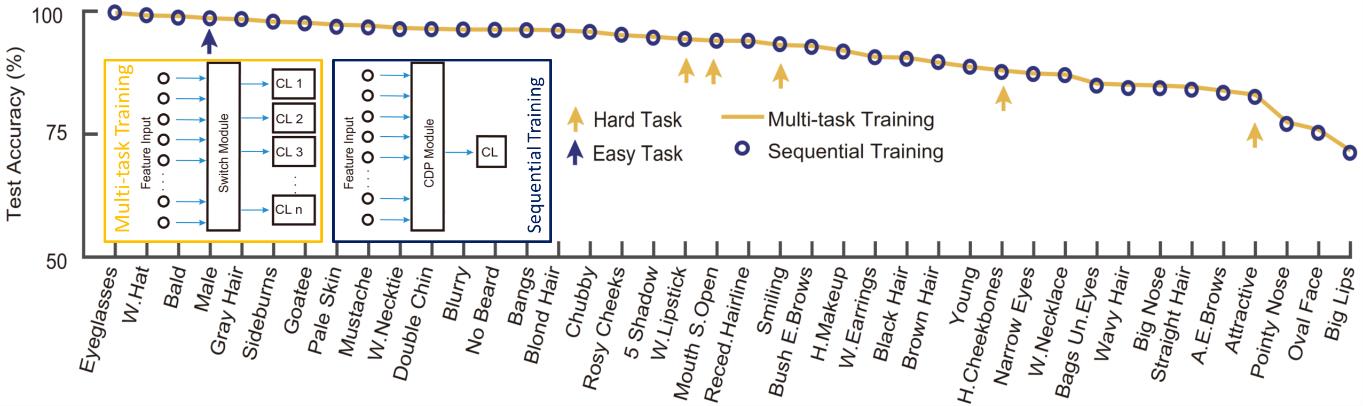
Performance of sequentially learning to classify faces by 40 different attributes (the blue dot) reveals nearly the same accuracy with results obtained by multitask training with 40 separate classifiers (the orange line).
To conclude, the orthogonal weights modification can overcome catastrophic forgetting, and the context-dependent processing module enables a single network acquiring numerous context-dependent mapping rules in an online and continual manner. By combining OWM with CDP, the Intelligent agents are expected to take continual learning to adjust to the complex and changeable environments, and finally reaching a higher level of intelligence.
Full Text:Continual Learning of Context-dependent Processing in Neural Networks
Contact:
ZHANG Xiaohan, PIO, Institute of Automation, Chinese Academy of Sciences
Email: xiaohan.zhang@ia.ac.cn