
Changing the Style of Facial Pictures with One Click
-- Researchers of Institute of Automation, CAS Proposes a Reference Guided Face Component Editing Method
Face portrait editing aims to manipulating a given face image to possess desired attributes or components. It has potential applications in movie industry, photo manipulation, and interactive entertainment, etc. The researchers from the Biometrics and Forensics Group of the Institute of Automation, Chinese Academy of Sciences, Qiyao Deng, Qi Li and Zhenan Sun, proposed a Reference Guided Face Component Editing Method (r-FACE) to learn the shape of target face components from reference images. This method achieves diverse and controllable face component editing, while still preserving the consistency of pose, skin color and topological structure. Compared to traditional algorithm and commercial PS algorithm, it has a significant improvement in visual effect. The paper namely Reference Guided Face Component Editing was accepted by the top academic conference IJCAI 2020.
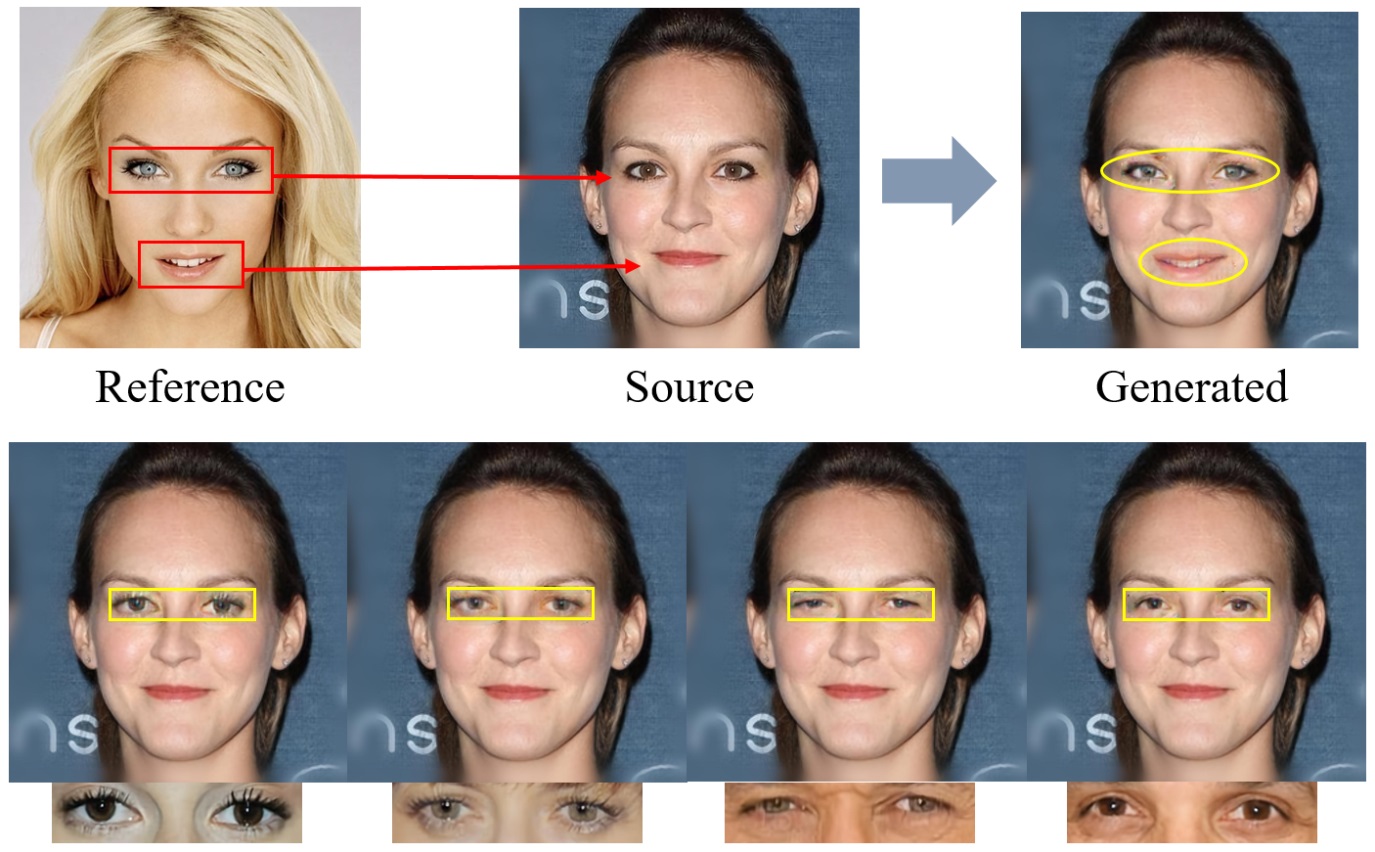
Fig. 1 The illustration of reference guided face component editing.
With advances in Generative Adversarial Networks [1] in recent years, tremendous progress has been made in face portrait editing. These approaches generally fall into two main categories: label-conditioned methods and geometry-guided methods. label-conditioned methods [2-3] edit face attributes with predefined labels as conditions. However, label-conditioned methods only focus on several predefined conspicuous attributes (e.g., hair color, age, mustache) thus lacking the flexibility of controlling shapes of high-level semantic facial components (e.g., eyes, nose, mouth). In order to tackle this, geometry-guided methods [4-5] propose to take manually edited mask or sketch as an intermediate representation for obvious face component editing with large geometric changes. However, directly taking such precise representations as a shape guide is inconvenient for users, which is laborious and requires painting skills.
To overcome the aforementioned problems, the team proposes a new framework namely Reference guided FAce Component Editing (r-FACE for short). r-FACE takes an image inpainting model as the backbone and takes a source image with target face components corrupted as the input, transferring the corresponding shape of facial components from reference images to missing area. Compared with the existing reference-based method [6] which requires paired images, r-FACE uses faces of arbitrary identities as reference images, thus further increasing the diversity of generated images. To supervise the proposed model, a contextual loss is adopted to constrain the similarity of shape between generated images and reference images, while a style loss and a perceptual loss are adopted to preserve the consistency of skin color and topological structure between generated images and source images. The framework of the method is shown in Fig. 2.
In addition, an example-guided attention module is designed to encourage the framework to concentrate on the target face components by combining attention features and target face component features of the reference image, further boosting the performance of face portrait editing. In summary, the framework breaks the limitations of existing methods: 1) shape limitation. r-FACE can flexibly control diverse shapes of high-level semantic facial components by different reference images; 2) intermediate presentation limitation. There is no need to manually edit precise masks or sketches for observable geometric changes.
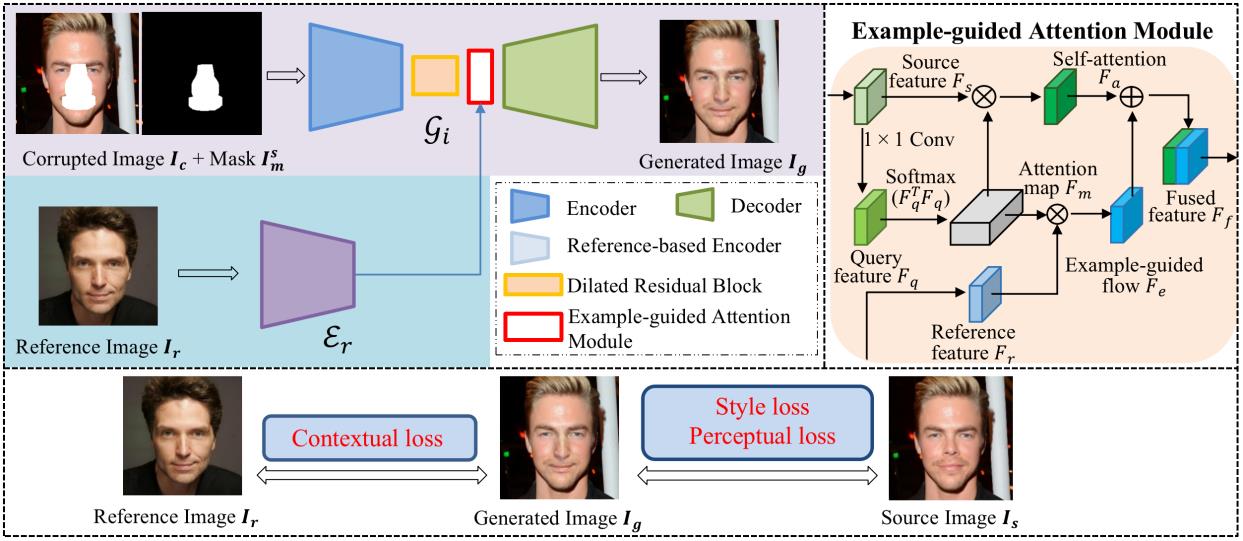
Fig. 2 The overall structure of proposed framework.
The proposed method is qualitatively and quantitatively analyzed on face attribute dataset CelebA-HQ. Experimental results show that this method generates high-quality and diverse faces with observable changes for face component editing. This is another progress of the team in the field of deep media forgery.

Fig. 3 Comparisons of (c) copy-and-paste, (d) AttGAN, (e) ELEGANT, (f) Adobe Photoshop and (g) r-FACE. The source and reference images are shown in (a) and (b), respectively.

Fig. 4 Illustrations of hybrid face components editing.
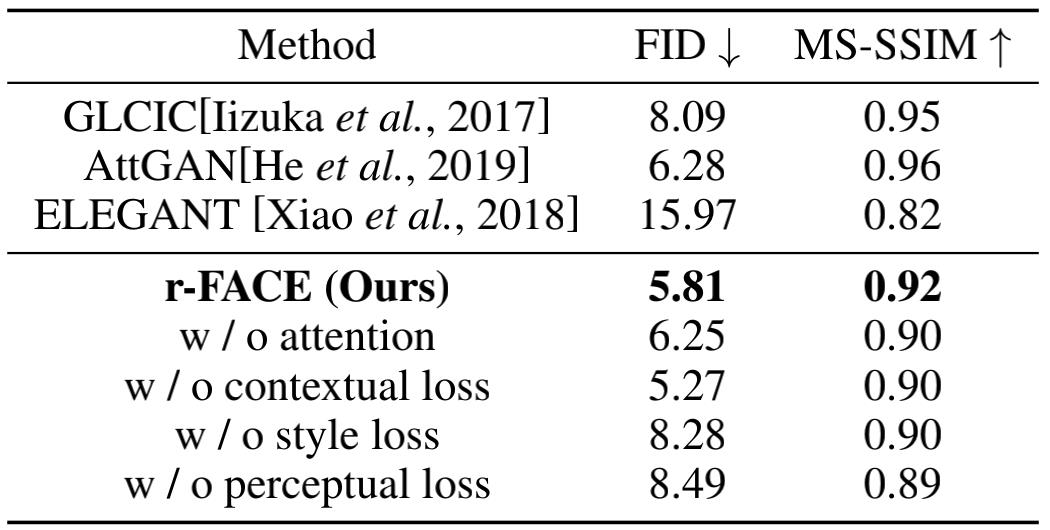
Tab. 1 Comparisons of FID and MS-SSIM on the CelebA-HQ dataset.
Read more: https://www.ijcai.org/Proceedings/2020/0070.pdf
References:
[1] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In NeurIPS, pages 2672–2680, 2014.
[2] Yunjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha, Sunghun Kim, and Jaegul Choo. StarGAN: Unified generative adversarial networks for multi-domain image-to-image translation. In CVPR, pages 8789–8797, 2018.
[3] Zhenliang He, Wangmeng Zuo, Meina Kan, Shiguang Shan, and Xilin Chen. AttGAN: Facial attribute editing by only changing what you want. IEEE TIP, 2019.
[4] Shuyang Gu, Jianmin Bao, Hao Yang, Dong Chen, Fang Wen, and Lu Yuan. Mask guided portrait editing with conditional GANs. In CVPR, pages 3436–3445, 2019.
[5] Youngjoo Jo and Jongyoul Park. SC-FEGAN: Face editing generative adversarial network with user’s sketch and color. In ICCV, October 2019.
[6] Brian Dolhansky and Cristian Canton Ferrer. Eye in-painting with exemplar generative adversarial networks. In CVPR, pages 7902–7911, 2018.
Contact:
ZHANG Xiaohan, PIO, Institute of Automation, Chinese Academy of Sciences
Email: xiaohan.zhang@ia.ac.cn